제목에 열거한 RMSE, MSE, MAE는 딥러닝 모델을 최적화 하는 데 가장 인기있게 사용되는 오차 함수들이다. 이번 포스팅에서는 (1) 이들의 특징을 알아보고, (2) 이 3 가지 손실 함수를 비교 분석해본다.
아래의 예를 보자. 어떤 모델이 학습 데이터를 입력받아 아래 테이블 내 수치들을 예측했다고 해보자. target은 prediction이 맞춰야 할 정답이고, epoch은 학습의 횟수를 가리킨다. Epoch 2에서, Prediction의 3번째 값인 2는 그것이 근접했어야 할 Target의 3번째 값인 7과 크게 벗어나게 예측했다는 의미에서 Outlier라는 점에 주목하자.

이들 값을 가지고 MSE, RMSE, MAE를 계산해보면 아래와 같다:

MSE의 특징
[1] Mean Square Error는 예측값과 정답의 차이를 제곱하기 때문에, 이상치에 대해 민감하다. 즉, 정답에 대해 예측값이 매우 다른 경우, 그 차이는 오차값에 상대적으로 크게 반영된다.
[2] 오차값에 제곱을 취하기 때문에 (1) 오차가 0과 1 사이인 경우에, MSE에서 그 오차는 본래보다 더 작게 반영되고, (2) 오차가 1보다 클 때는 본래보다 더 크게 반영된다.
[3] 모든 함수값이 미분 가능하다. MSE는 이차 함수이기 때문에 아래와 같이 첨점을 갖지 않는다.

RMSE의 특징
[1] MSE에서 루트를 취하기 때문에, [1], [2] 에서 나타나는 MSE의 단점이 어느 정도 해소된다.
[2] MSE는 부드러운 곡선형으로 오차 함수가 그려지지만, RMSE는 그 MSE에서 루트를 취하기 때문에 미분 불가능한 지점을 갖는다. 아래 Figure 2는 RMSE 함수에 대한 예시이다.
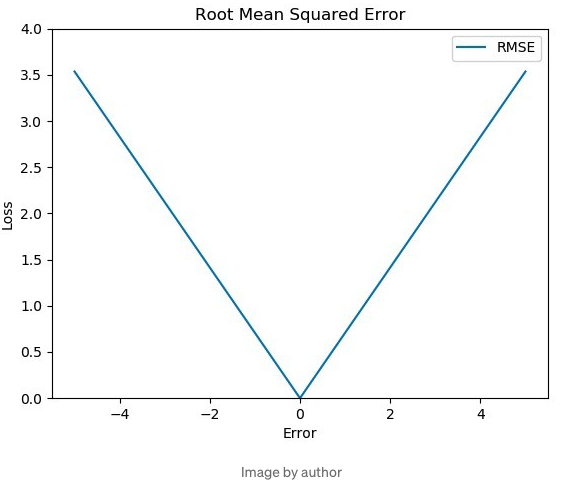
[3] MSE 보다 이상치에 덜 민감하다. 이 RMSE은 이상치에 대한 민감도가 MSE와 MAE 사이에 있기 때문에, 이상치를 적절히 잘 다룬다고 간주되는 경향이 있다. (아래에서 자세히 다룰 예정)
MAE의 특징
[1] 이상치에 둔감 혹은 강건robust하다. 그 이유는 Figure 1에서 보듯이, (3)에 해당하는 MAE는 위 MSE, RMSE에 비해, 오차값이 outlier의 영향을 상대적으로 크게 받지 않는다.
[2] 함수값에 미분 불가능한 지점이 있다. 아래 Figure 3의 MAE를 표현한 함수의 최솟값은 첨점이기 때문에 미분이 불가능하다. (고등과정 미분에 대해 복습하고자 한다면 Reference [4]를 참고)
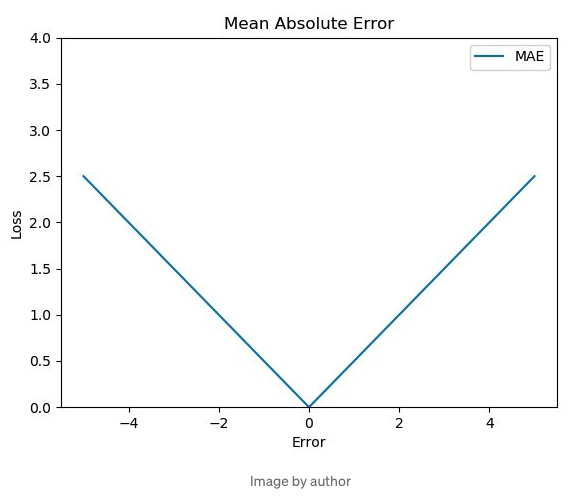
[3] 모든 오차에 동일한 가중치를 부여한다. 이는 MSE, RMSE와 대조된다.
3 가지 손실 함수에 대한 비교 분석
- MSE는 이상치에 대해 너무 민감하여, 모델의 학습을 불안정하게 만들 가능성이 크다. 현실 세계에서 마주하는 많은 데이터에는 이상치가 있고, 그 중 어떤 경우에 이상치가 처리되지 않을 때가 있는데, 그러한 경우 MSE를 이용한다면, 이상치에 민감하게 학습되기 때문에 학습 과정이 불안정할 것이다. 이 불안정함은 결국 모델의 피팅fitting을 방해하여 목적에 맞는 좋은 성능의 모델을 얻는 데 악영향을 끼칠 것이다.
- 그렇다면, MSE에 루트를 취하여 이상치에 대한 민감도를 줄인 RMSE와 절대값을 취하는 MAE 는 어떤 차이가 있는가? MAE는 오차들의 절댓값의 평균을 계산한다는 점에서, 모든 examples에 대한 오차에 동일한 가중치를 부여한다. 반면에, RMSE는 각 example에 제곱을 취한 뒤 평균을 구하고, 그것에 루트를 씌우는 것이기 때문에, 각 오차가 다른 가중치를 갖는다. 아래 그림을 보자.
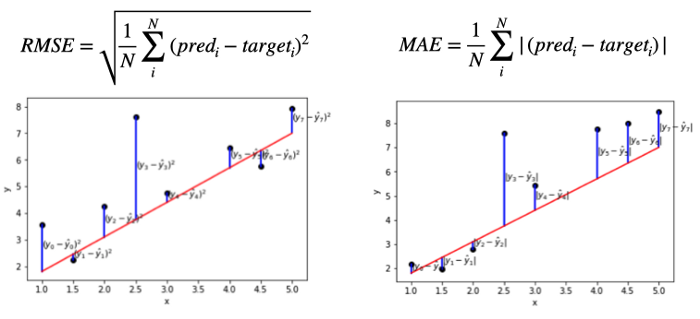
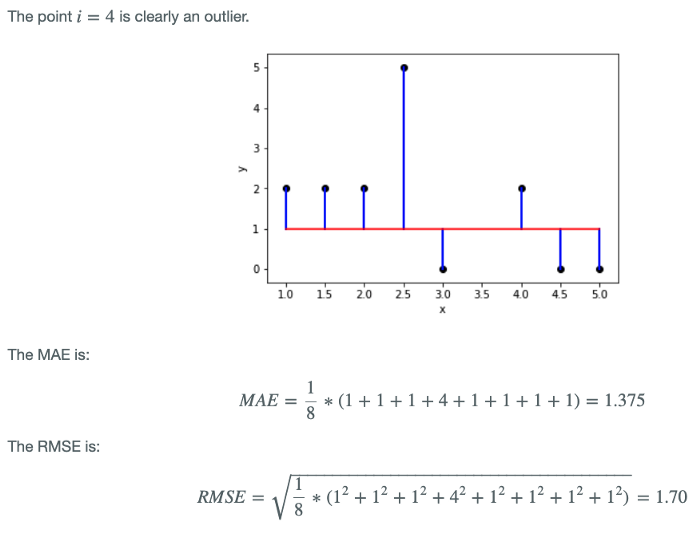
오른쪽 그래프인 MAE의 경우에, 각 examples에 대한 오차는 모두 동일하게 가중되어 고려되고 있다. 반면에, 왼쪽 그래프인 RMSE는 0과 1 사이의 오차는 더 작게, 1 보다 큰 오차는 더 크게 가중되어 고려되고 있다. 아래 그림에서 계산한 것을 참고할 때, 하나의 Outlier가 있는 경우, MAE는 다른 examples과 outlier를 동일하게 가중하여 고려하기 때문에 비교적 loss값이 낮게 나오지만, RMSE 경우에는 루트를 취했음에도 불구하고, outlier가 다른 examples 보다 가중되어 고려되기 때문에 비교적 loss값이 크게 나타난다. MSE였더라면 있었다면, 손실 값은 RMSE보다도 훨씬 더 컸을 것이다.
언제 어떤 loss를 사용하는가
- 약간의 이상치가 있는 경우, 그 이상치의 영향을 적게 받으면서 모델을 만들고자 할 때, MAE를 쓰는 것이 적절하다. 전술했듯이, MAE는 이상치에 대해 강건robust하기 때문에 이상치에 영향을 덜 받는다. 이는 이상치를 포함한 훈련 데이터에 적합하게 학습되어 unseen 데이터에 대해 낮은 성능을 보이게 하는 오버 피팅을 방지하는 데 도움이 될 수 있다.

하지만 MSE 경우에는 이상치에 민감하게 반응하여 학습하기 때문에, 손실 함수가 이상치에 의해 발생한 오차로부터 비교적 많은 영향을 받는다.

그러한 탓에, 이상치까지 고려하여 모델 일반화가 이루어진다. 하지만 이것이 모든 경우에 일반화를 제대로 하지 못했다고 간주될 수 없다. 어떤 경우에는 이상치를 무시하여 일반화할 필요가 있고 (MAE 쓰는 경우), 다른 경우에는 이상치도 고려하여 일반화(MSE 쓰는 경우)할 필요가 있기 때문이다.
앞에서 설명했듯이, RMSE는 MSE 보다 이상치에 대해 상대적으로 둔감하다. 하지만 이는 MAE처럼 모든 error에 동일한 가중치를 주지 않고, error가 크면 더 큰 가중치를 작으면 더 작은 가중치를 준다는 점에서, 여전히 이상치에 민감하다고 간주될 수 있다. 따라서 모델 학습 시 이상치에 가중치를 부여하고자 한다면, MSE에 루트를 씌운 RMSE를 채택하는 것은 적절하다.
Copyright ©️ 2022 (Jaeyoung Cheong) all rights reserved
References
[2] https://dailyheumsi.tistory.com/167
[4] https://m.blog.naver.com/alwaysneoi/100135882596
[5] https://jmlb.github.io/flashcards/2018/07/01/mae_vs_rmse/
[6]https://devstarsj.github.io/data/2018/10/22/kaggle.coursera.competition.03.01/
'머신러닝과 인공지능' 카테고리의 다른 글
| 통계/머신러닝 기반의 시계열 이상치(Anomaly) 탐지 조사 (2) | 2023.01.20 |
|---|---|
| 머신러닝을 이용한 블록체인 상에서의 부정거래 탐지 (3) | 2022.12.12 |

