1. 들어가며
최근 세간의 블록체인에 대한 관심이 높아짐에 따라 머신러닝 분야에서도 이에 대한 연구가 활발히 진행되고 있다. 블록체인 분야에 머신러닝을 접목한 분야로는 부정거래 탐지 시스템(Fraud Detection System, FDS), 가상자산 가격 예측, 거래소 주소 식별, NFT 공정가 예측 등이 있는데 이들 중 가장 많은 연구가 이루어진 분야는 FDS일 것이다. 실제로, 악의적인 의도를 가진 많은 스캐머는 블록체인의 익명성을 악용하여 비트코인, 이더리움을 통해 폰지 사기, 스캠 사기, 자금 세탁 등을 자행하고 있다. 미국의 블록체인 데이터분석 업체인 Chainalysis에 따르면 [5], 2021년도에 가상자산을 통한 스캠 범죄 피해액은 약 80억 달러에 달한다고 한다. 이는 전년도인 2020년에 비해 약 80% 증가한 수치이다. 다수의 가상자산 거래소에서는 이 같은 범죄를 예방하기 위해 부정거래 탐지 솔루션을 연구 개발하여 발전시키고 있다 [6], [7]. 알려진 바에 따르면, 국내의 한 암호화폐 거래소에서는 머신러닝 기반으로 가상자산에 대한 이상금융거래 탐지 솔루션을 서비스에 도입했다고 한다 [8]. 나아가, 거래소 뿐만 아니라, 블록체인 전문 기업 [17], [18] 에서도 머신러닝 기반의 암호화폐에 대한 부정거래 탐지 연구를 진행하고 있고, 이들 중 웁살라시큐리티는 현재 개발된 솔루션을 상용화한 사실을 공개한 바 있다.
하지만 사실 국내 타 금융권에서는 이미 몇년 전부터 머신러닝 기반 이상거래 탐지 연구를 진행해왔다. 2013년에 금융위원회가 ‘금융 전산 보안강화 대책’을 통해 금융권에 FDS 구축을 권고함에 따라, 주요 은행사에서 이상금융거래 탐지 시스템을 개발해왔다. 2018년도부터는 인터넷은행, 카드사 등에서도 이 시스템 개발을 진행중인 것으로 알려져 있다 [9]. 이들 중 신한은행 [11], 카카오페이 [14] 등에서는 이미 머신러닝 기반으로 FDS를 연구 및 개발하고 있는 것으로 보도된 바 있다.

머신러닝 기반 FDS는 룰 기반의 그것보다 다음 같은 이점을 가질 것으로 기대된다는 점에서 발전 가능성이 크다고 보여진다.
- ML 접근은 부정거래 탐지 전문가 집단의 지식에 의존하지 않고 기계가 데이터를 경험적으로 학습하기 때문에 FDS 개발에 요구되는 비용, 시간적인 자원을 절약할 수 있다.
- 룰 기반 시스템은 인간이 입력한 조건에 의해 작동하기 때문에 새로 입력되는 정상/사기 패턴에 대한 식별 조건 업데이트가 자동으로 이루어지지 않는다. 반면에, ML 기반 시스템은 새로 입력되는 데이터를 경험적으로 학습하여 분류하기 때문에 Concept Drift을 용이하게 대응할 수 있다.
- ML 기반 시스템은 인간이 감지하지 못하는 미묘한 사기 패턴까지도 학습하여 식별하기를 기대할 수 있다.
물론, ML 기반 시스템을 도입할 때 마주할 수 있는 곤경도 있다. 가장 도전적인 어려움은 전문가 시스템과 달리, ML 시스템은 정상/사기 여부가 라벨링된 데이터가 요구된다는 점일 것이다. 사실 이것은 거의 모든 분야에서 ML 시스템을 구축할 때 마주하는 어려움이다. 하지만 블록체인 분야는 비교적 쉽게 데이터를 얻을 수 있다. 블록체인의 투명성을 이용해 원하는 모든 트랜잭션 데이터에 접근할 수 있으며, CryptoscamDB [10] 같은 곳에서는 사기 거래에 대한 라벨링 데이터도 제공하고 있기 때문이다. 더욱이, 최근들어 머신러닝 연구 영역에서는 준지도학습(Semi-Supervised Learning) 연구가 활발히 진행됨에 따라 소량의 라벨 데이터셋만을 가지고서도 보다 좋은 일반화 성능을 가진 모델 개발을 기대할 수 있게 되었다.
아래에서 나는 가상자산에 대한 FDS에 대해 공부하면서 읽었던 흥미로운 5가지 연구를 소개한다. 이 5가지는 모두 어떻게 투명하게 공개된 블록체인 데이터를 이용하여 모델의 사기 탐지 성능 향상을 위해 더 정보적인 임베딩을 얻을 수 있는 지에 대한 방법을 제안한 연구들이다. 첫 파트에서는 스마트컨트랙트의 바이트코드를 이용한 연구를 소개하고, 나머지 부분에서는 그래프 신경망을 응용한 연구를 소개한다.
2. 기존 연구
2.1 Bytecode 활용
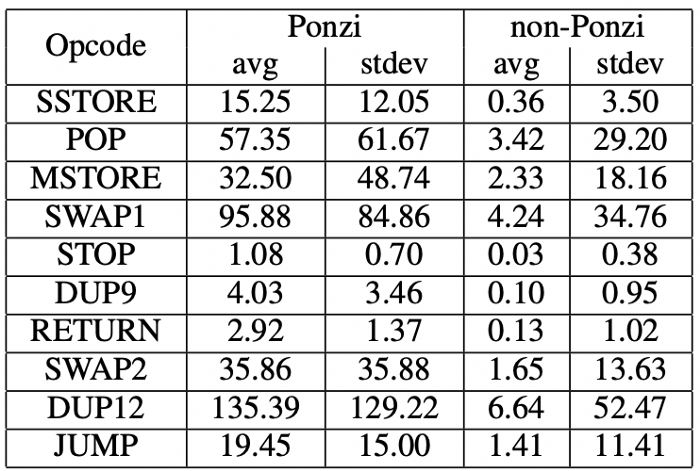
다수의 머신러닝 기반의 가상자산에 대한 부정거래 탐지 연구는 [12]와 같이 지갑 주소의 트랜잭션 원천 데이터으로부터 얻은 통계적 특징에 이미 잘 알려진 머신러닝 및 신경망 알고리즘을 적용하는 정도에 지나지 않았다. 하지만 스마트 컨트랙트 코드를 이용하거나 네트워크 구조를 이용하는 독창적이고 세련된 아이디어도 제안되고 있다. [1]에서는 바이트코드로 인코딩된 스마트 컨트랙트 소스 코드를 OPCODE로 변환한 뒤, OPCODE의 발생 통계량과 트랜잭션의 통계량을 함께 학습시킨다.
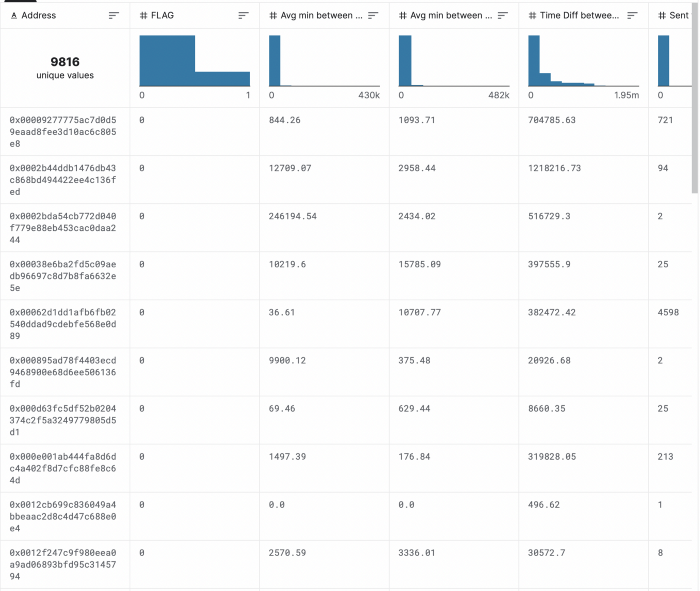
또한, [1]에서는 Gini 계수를 이용하여 임의의 지갑 주소의 송수신액의 불평등성을 피처로 계산한다. 저자는 폰지 사기의 경우 초기 투자자는 투자한 뒤 더 큰 보상을 받을 것이지만, 나중 투자자는 투자한 뒤 어떤 보상도 회수를 하지 못하는 양상을 보이는데, 이것을 포착하기 위해 지니 계수를 사용하는 것은 유용할 것이라고 생각한다.
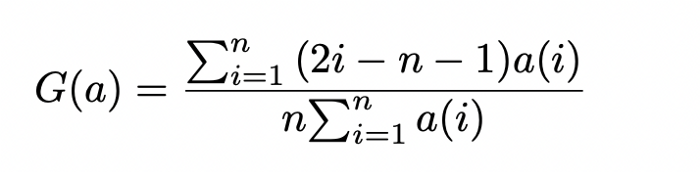
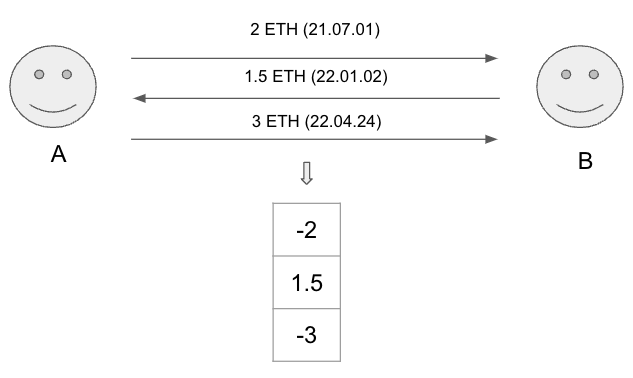
여기서 a는 분포이고, n은 a 내 participant 개수이다. 위 식에 대한 이해를 돕고자 예를 들자면 아래와 같다.

위 [그림2]에서 볼 수 있듯이, 두번째 그림인 왼쪽의 participant의 스코어가 더 큰 경우 (트랜잭션 사례에서는 첫 거래에 이더를 가장 많이 보내거나 받은 경우)와 세번째 그림인 오른쪽의 participant가 더 큰 경우 (트랜잭션 사례에서는 마지막 거래에 이더를 가장 많이 보내거나 받은 경우)의 지니계수 결과는 정반대이고, 첫번째 그림과 나머지 그림의 지니계수 절댓값 차이는 비교적 크다. 이는 지니계수의 절댓값은 폰지 사기 패턴에 유사한지 여부를 결정할 때 정보적일 수 있음을 함축하는 것으로 보인다.
[3]에서도 스마트컨트랙트 바이트코드를 모델 학습을 위한 피처로서 이용하는데, 여기서는 [1]과는 달리, 이 바이트코드를 n-gram으로 분절하여 모델에 학습시킨다. 예를 들어, “0xeaa18152488ce5959073c9c79c89” 라는 바이트 코드가 있다면, 이것을 2-gram으로 분절할 때, “0x”, “ea”, “a1”, “81”, … 이 될 것이다. 이 연구에서는 n-gram의 n이 얼마인지에 따라서 모델 성능에도 유의미한 변화가 있음을 보였다. 이 논문의 실험 결과에 따르면, 2-gram, 3-gram으로 분절할 때 학습된 신경망 모델이 가장 좋은 폰지(Ponzi) 사기 패턴 식별 능력을 얻었다.
2.2 Graph Neural Network 응용
최근 신경망 기반의 가상자산에 대한 사기 탐지 연구 트렌드는 그래프 신경망을 적용한 방법론인 것 같다. [4]를 필두로 하여 다수의 연구에서 비트코인, 이더리움에 대한 그래프 신경망 기반의 부정거래 탐지 방법을 제안하기 시작했다. [4]에서는 그래프 신경망의 대표적인 모델인 Graph Convolutional Network(GCN)을 그대로 차용했다.
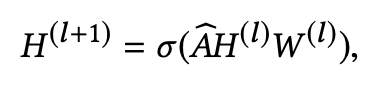
위 [식1]에 대해 간략히 설명하자면, 여기서 H는 embedding matrix이고, A는 Adjacency Matrix, W는 Trainable Weight를 가리킨다. 시그마는 Activation Function이다. 이 [식1]은 현재 레이어 (l)에서, AHW를 곱한 뒤 activation function을 통과하면 다음 레이어 (l+1)에서의 임베딩 행렬을 구할 수 있음을 뜻한다.
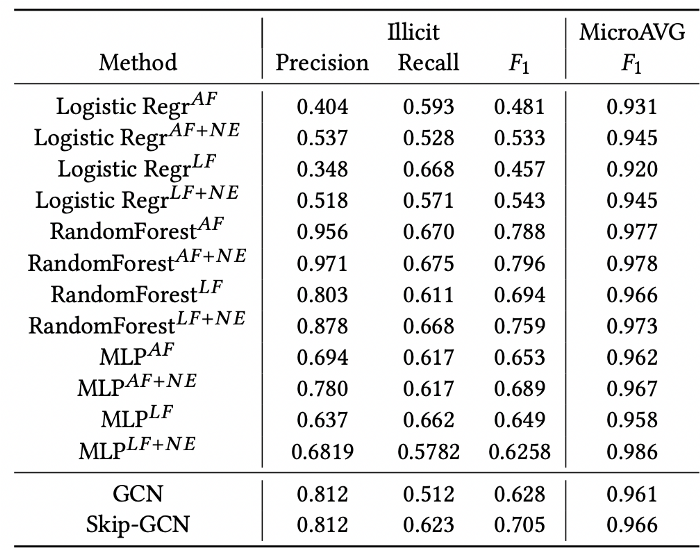
해당 논문[4]에서 진행한 실험 결과에 따르면, 부정 거래인지 정상 거래인지 여부를 식별하는 이진 분류 태스크에서, 비트코인 FDS 모델을 만들기 위해 GCN을 도입할 시 (graph 정보에 agnostic한) Logisic Regression 모델을 사용할 때 보다 더 좋은 성능을 보인다. 하지만 Random Forest, MLP 모델의 성능이 GCN, Skip-GCN 보다 좋은 경우가 있는데, 저자는 이 결과에 대해 모델 학습에 사용한 Input-features에 이미 그래프 정보가 반영되어 발생한 것이라고 해석한다.
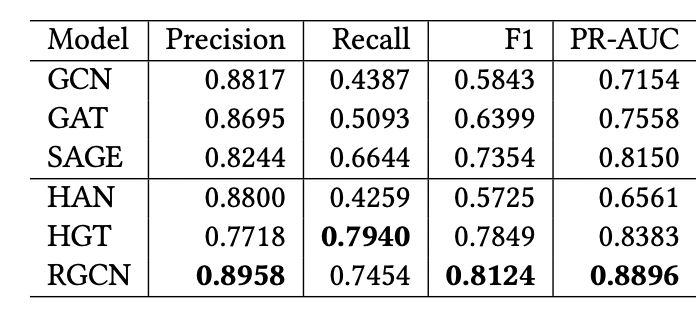
[13]은 Heterogeneous Graph Neural Network를 이더리움 사기 탐지에 응용한 아이디어를 제안한다. 앞에서 보았던 [4]의 아이디어는 Homogeneous GNN에 대한 연구였다. 이것은 <사기 유형을 가진 nodes> 만을 고려한다 점에서 homogeneous 하다고 여겨진다. 반면에, [13]에서는 <사기 유형을 가진 nodes> 뿐만 아니라 <가상자산 거래소 소유 지갑(exchange) 유형을 가진 nodes> 또한 이용한다는 점에서 heterogeneous 하다고 여겨진다. 이 같이 heterogeneous GNN을 이용하면 모델 학습 시에 homogeneous GNN 보다 더 informative features를 얻을 수 있다. [13]의 저자들은 거래소 유형 주소는 직접적으로 부정 거래 주소를 탐지하는 데 연관이 있는 것은 아니지만, 부정 거래라고 의심되는 트랜잭션 및 주소를 탐지하는 데 힌트가 될 것이라고 가정한다. 그들은 본고에서 fraud 탐지 모델을 만들기 위해 이 이질적인 exchange 유형 주소와 fraud 유형 주소 간의 “edge-type”를 구성하는데 사용한다.
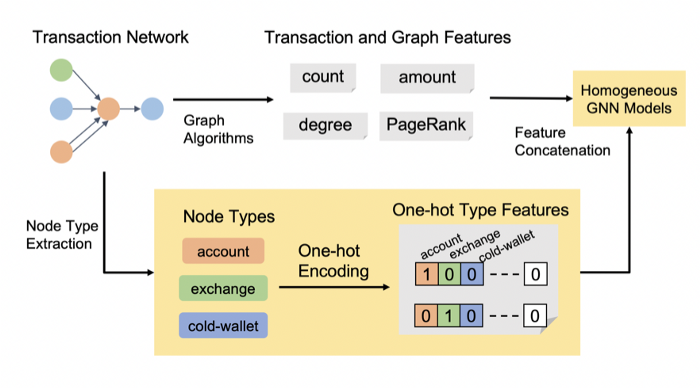
저자는 위에서 구성한 edge-type을 동원하여 기존에 제안된 Heterogeneous GNN 모델에 트랜잭션의 통계적 특징과 함께 학습시킨다. 저자가 사용한 피처는 Homogeneous GNN을 예로 들 때 아래 [그림5]와 같다. 기존 연구들과 유사하게 본 연구에서도 모델 학습을 위해 트랜잭션의 통계적 특징을 이용했을 뿐만 아니라 각 노드의 유형 또한 One-Hot 인코딩 방식으로 라벨링했다는 점에서는 종래의 연구와 차이가 있다.
[13]의 Homogeneous vs Heterogeneous GNN을 비교한 실험 결과는 아래와 같다.
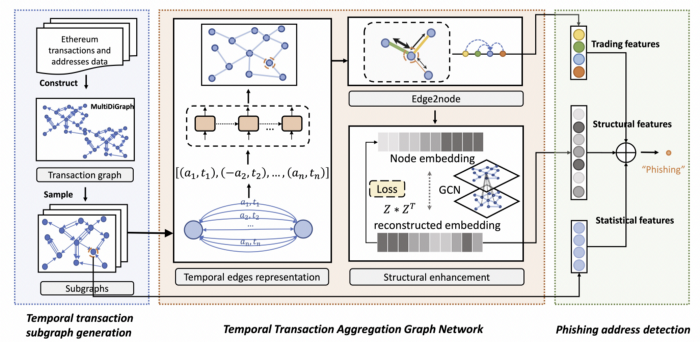
3. TTAGN (Temporal Transaction Aggregation Graph Network)
개인적으로, 지금까지 제안된 가상자산에 대한 사기 탐지에서 가장 흥미로웠던 논문은 이 TTAGN [2]이다. 그 이유는 지갑 주소의 트랜잭션에 대한 Temporal information을 모델에 학습시키기 때문일 것이다. 기존 연구는 모델 학습을 위해 트랜잭션 정보를 통계적 특징 (예컨대, 타깃 주소가 보낸 이더 양의 총합, 보낸 이더의 최대값 등)만을 이용했다면, [2]에서는 타깃 주소의 트랜잭션이 시간이 지남에 따라 어떻게 변하는지에 대한 정보를 학습했다는 점에서 특별하다. (실제 논문에서 거래 시간도 features로 사용한다.)
기 제안된 아이디어들과 같이 트랜잭션 레코드의 contextual 정보를 무시한 채 오직 트랜잭션의 통계적, 구조적 특징만을 사용한다면 weak node representation 문제가 야기될 수 있다. 즉, 이것은 레코드의 contextual 정보를 활용할 때 만큼 풍부한 representation을 얻지 못함을 함축한다.
이러한 기존 연구의 한계를 극복하기 위해 TTAGN에서는 3 가지 구성 요소로 이루어진 아키텍처를 소개한다.
- Temporal Edge Representation: 이더리움 플랫폼 상의 지갑 주소 간 거래 기록에서 temporal information을 추출한다.
- Edge2node module (To get trading features): 지갑 주소(node) 사이에 있는 edge representation은 네트워크의 topological interaction 정보를 더 풍부하게 하기 위해 aggregation 된다.
- Structure Enhancement module: 네트워크의 구조 정보 학습
3.1 Temporal Edge Representation
Motivation
트랜잭션 정보에는 transaction direction, amount, timestamp 등이 포함되는데, 이는 phishing address와 normal address 간의 차이를 반영한다. 저자는 이 점을 고려하여 거래 레코드의 시간적(temporal) 또는 맥락적 (contextual) 정보를 이용하면 노드의 Representaion이 향상될 것이라고 말한다.
A proposed idea
그렇다면, Temporal Transaction 정보를 어떻게 Edge representation으로 넣을 수 있을까? 저자는 Transaction이라는 sequential한 데이터를 처리하기 위해 대중적인 RNN 계열 모델인 LSTM을 사용한다.
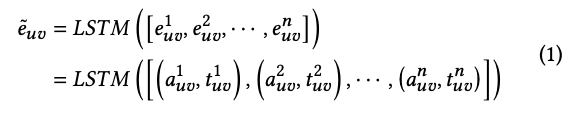
위에서 최종적으로 계산된 e(uv)_tilde는 edge embedding이고, (u,v)는 노드 pair를 가리킨다. 따라서 위 식에서 e(uv)1, e(uv)2, … e(uv)n은 두 개의 지갑 주소 간에 이루어진 n 개의 트랜잭션의 embeddings 이다. 또한 이 n개의 embedding을 만들기 위해 a(uv)i, t(uv)i 가 input으로 들어가는데 이들은 각각 amount와 timestamp 이다. 저자는 송수신 경우를 구분하기 위해 sending인 경우 amount를 +로, receving인 경우는 -로 표기한다.
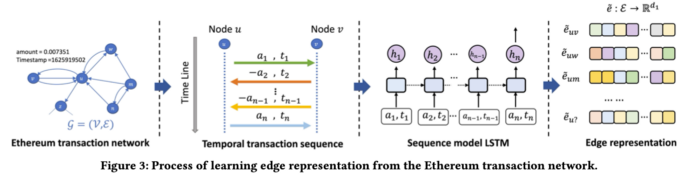
3.2 Edge2node module
Motivation
이전 연구들에서 사용되어 온 노드 (이더리움 지갑 주소)에 대한 manualy-designed 통계적 특징 (가령 송금 횟수)은 모델에 weak node representation만을 제공할 뿐이었다. 하지만 각 지갑 주소는 동시에 여러 다른 주소들과 interaction을 하는데, TTAGN에서는 이 interaction을 representation으로 가공한다. 이렇게 만들어진 representation은 각 node representation에 다른 정보를 제공하는데, 이 정보는 각 월렛 주소의 fraud 스코어에 영향을 주기 때문에 모델의 식별 성능 향상에 이점을 제공한다.
A proposed idea
TTAGN은 여러 월렛(nodes)을 둘러싼 트랜잭션(edges) representations을 집계aggregated하여 월렛 간 관계 구조를 모델로 하여금 학습할 수 있게 해준다. 더욱이, Edge2node 모듈에서는 유사한 트랜잭션 행태를 포착하기 위해 Attention 기법을 적용함으로써 trading features를 생성하게 해준다. 이 edge2node 모듈은 인접한 edges의 weights을 학습하고 이들을 집계함으로써 expressive node representations을 얻게 해준다.
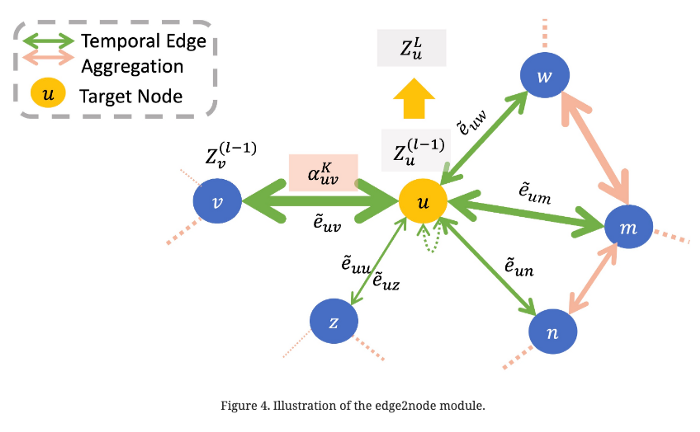
Edge2node에서 Attention을 적용하여 임의의 node u의 feature를 얻기 위해서는 아래 같은 과정이 요구된다.

여기서 주목할 점은 h_v는 (위 그림8을 참고할 때) 노드 u와 노드 v 사이에 있는 edge의 features라는 점이다. 즉, h_v는 위 그림5에서 얻은 features다. 새로운 edge features인 e_uv를 만들기 위해 node feature인 h_u와 edge feature인 h_v를 concatenation하는 것이다. 위 식3을 통해 얻은 z_u는 임의의 node u에 대해 attention을 통해 구해진 Embedding이 된다.
3.3 Structure Enhancement module
위에서 소개된 2 가지 모듈은 모두 transaction features를 효과적으로 추출하기 위해 사용되었다. 이 <Structure Enhancement> 모듈에서는 comprehensive한 노드 표현력을 얻기 위해 node structure features 를 추출한다. 방법은 매우 단순하다. 이것은 아래 [그림9]로 간략히 소개만 하고 스킵하겠다.

3.4 Experimential result
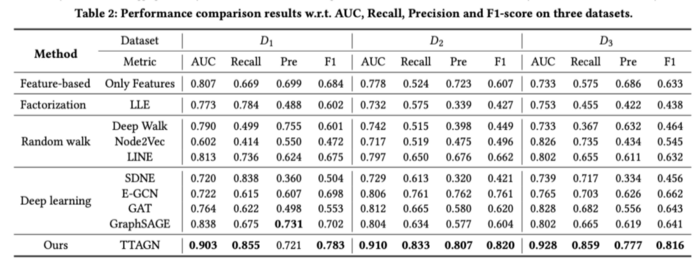
실험 결과는 아래 표3에서 TTAGN의 성능이 보여주는 바와 같이 타 방법론에 비해 매우 우수한 편이다. 아래에서 D1, D2, D3 3개의 데이터셋이 있는데, 이들은 모두 다른 샘플로 구성된 데이터셋이다. 저자는 여러 데이터셋에 대해 실험을 진행할 때도 일관적으로 TTAGN 방법론의 분류 성능이 우수하다는 점을 어필한다.
아래 그림10에서 진행한 Ablation Study은 각 모듈의 식별 성능 향상 기여도를 보여준다. 아래 표에서 TTAGN에 해당하는 것이 전술된 3가지 모듈을 모두 사용한 경우이고, TTAGN/e 같이 표기된 것은 특정 모듈 (edge2node)만을 제외한 모델을 가리킨다. 아래 결과를 미루어볼 때, Structure Enhancement 모듈을 제외한 나머지 2 가지 모듈의 효용성은 매우 높다. 특히, Recall 경우, Edge2node를 사용한 경우와 그렇지 않은 경우의 차이는 최대 0.2 정도 차이가 나는 것을 볼 수 있다.
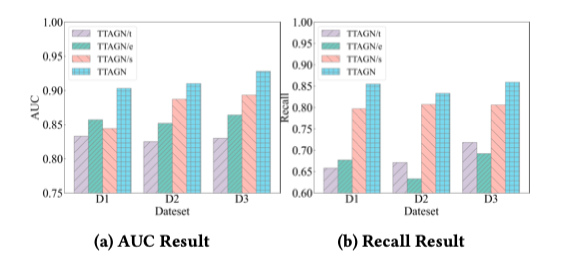
위 결과는 월렛들의 transaction history 정보를 모델 학습을 위한 features로 활용하는 것이 매우 유용하다는 점을 함축한다고 볼 수 있다.
4. 나가며
가상자산, 블록체인 분야에서 머신러닝을 적용하는 연구는 점점 다양해지고 고도화되고 있다. 위에서 살펴보았듯이, 신경망 기반의 가상자산에 대한 부정거래 탐지 연구 분야에서도, 현재는 고전적인 머신러닝 알고리즘을 적용하고 단순한 신경망 모델을 적용하던 2017년 이전 보다 더 다양하고 세련된 방식의 연구가 진행되고 있다. 하지만 여전히 문제는 남아있다. 이 연구가 실용적이기 위해서는 더 신뢰할만한 데이터셋 구축 프로세스 안에서 라벨링된 데이터를 수집해야 할 것이다. Cryptoscam DB 또는 Etherscan [15] 등에서 제공되는 라벨링 데이터는 수집 출처 및 방법이 불분명하기 때문에 신뢰하기 어렵다는 난점이 있다. 또한, 개인적인 경험에 비추어 볼 때, 다수의 블록체인 전문 회사에서는 인공지능 기술을 블록체인 기술의 대척점에 있는 것으로 여겨 머신러닝 활용에 초점을 맞추는 경우가 드문 경향이 있다. 설상가상으로, 블록체인 산업 내에 머신러닝 전문가는 매우 드물다. 대부분의 ML 전문가는 비전, 자연어, 오디오, 추천시스템, 게임 산업 등에 포진되어 있는 것 같다. 가상자산 및 블록체인 시장이 성장함에 따라 이 분야에서도 패턴인식 및 머신러닝 기술이 요구되는 여러 문제에 맞닥뜨리게 될 것이다. 향후 더 많은 머신러닝 관련자가 블록체인 산업에도 관심을 갖게 되기를 기대하며 글을 마친다.
Copyright ©️ 2022 (Jaeyoung Cheong) all rights reserved
References
[1] Jung, Eunjin, et al. “Data mining-based ethereum fraud detection.” 2019 IEEE International Conference on Blockchain (Blockchain). IEEE, 2019.
[2] Li, Sijia, et al. “TTAGN: Temporal Transaction Aggregation Graph Network for Ethereum Phishing Scams Detection.” Proceedings of the ACM Web Conference 2022. 2022.
[3] Hu, Huiwen, Qianlan Bai, and Yuedong Xu. “Scsguard: Deep scam detection for ethereum smart contracts.” IEEE INFOCOM 2022-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS). IEEE, 2022.
[4] Weber, Mark, et al. “Anti-money laundering in bitcoin: Experimenting with graph convolutional networks for financial forensics.” arXiv preprint arXiv:1908.02591 (2019).
[5] 이한수, “체이널리시스 “스캠 피해, 전년보다 81% 증가한 9조 원””「메타미디어」, 2022.01.28
[6] 김가영, “빗썸, FDS강화·거래량 폭증에 고객센터 ‘과부하’” 「팍스넷뉴스」, 2021.04.09
[7] 원재연, “코인원 “예외 없이 원칙 준수가 핵심”” ,「팍스넷뉴스」,2022.08.17
[8] 박세아, “가상자산거래소, ‘이상금융거래탐지’로 사기 및 범죄 미리 잡아낸다” 「디지털데일리」, 2022.09.16.
[9] 금융보안원, “머신러닝 기반의 이상거래 탐지 시스템 동향", 2017.08
[10] https://cryptoscamdb.org/
[11] 김대훈, “신한은행, 금융권 최초 ‘AI 이상행동탐지 ATM’ 도입”「한경금융」, 2022.03.07
[12] Farrugia, Steven, Joshua Ellul, and George Azzopardi. “Detection of illicit accounts over the Ethereum blockchain.” Expert Systems with Applications 150 (2020): 113318.
[13] Kanezashi, Hiroki, et al. “Ethereum Fraud Detection with Heterogeneous Graph Neural Networks.” arXiv preprint arXiv:2203.12363 (2022).
[14] 현화영, “카카오페이 “송금 전 사기이력 확인하고, 잘못 보내면 바로 신고하고”” 「세계일보」, 2022.09.07
[16]http://wiki.hash.kr/index.php/%EB%9E%8C%EB%8B%A4256%E3%88%9C
[17] https://www.coindeskkorea.com/news/articleView.html?idxno=71103
'머신러닝과 인공지능' 카테고리의 다른 글
| 통계/머신러닝 기반의 시계열 이상치(Anomaly) 탐지 조사 (2) | 2023.01.20 |
|---|---|
| 언제 MSE, MAE, RMSE를 사용하는가 (0) | 2022.12.12 |

